6. Model Predictive Control
The general idea of figuring out what moves to make using optimisation at each time step has become very popular due to the fact that a general version can be programmed and made very user friendly so that the intricacies of multivariable control can be handled by a single program.
In this notebook I will show how a single time step’s move trajectory is calculated. We’ll use the same system as we used for the Dahlin controller
[1]:
import numpy
import scipy.signal
import scipy.optimize
import matplotlib.pyplot as plt
%matplotlib inline
We start with a linear model of the system
[2]:
G = scipy.signal.lti([1], [15, 8, 1])
[3]:
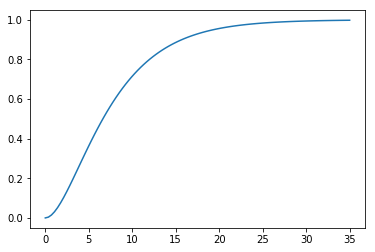
plt.plot(*G.step())
[3]:
[<matplotlib.lines.Line2D at 0x1c146a8390>]
Our goal is to find out what manipulations must be made (changes to \(u\)) in order to get the system to follow a specific desired trajectory (which we will call \(r\) for the reference trajectory). We will allow the controller to make a certain number of moves. This is called the control horizon, \(M\). We will the observe the effect of this set of moves (called a “move plan”) for time called the prediction horizon (\(P\)).
Controller parameters
[4]:
M = 10 # Control horizon
P = 20 # Prediction horizon
DeltaT = 1 # Sampling rate
[5]:
tcontinuous = numpy.linspace(0, P*DeltaT, 1000) # some closely spaced time points
tpredict = numpy.arange(0, P*DeltaT, DeltaT) # discrete points at prediction horizon
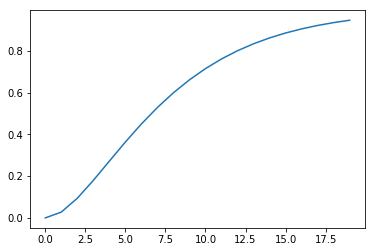
We choose a first order setpoint response similar to DS or Dahlin
[6]:
tau_c = 1
r = 1 - numpy.exp(-tpredict/tau_c)
For an initial guess we choose a step in \(u\).
[7]:
u = numpy.ones(M)
Initital state is zero
[8]:
x0 = numpy.zeros(G.to_ss().A.shape[0])
[9]:
def extend(u):
"""We optimise the first M values of u but we need P values for prediction"""
return numpy.concatenate([u, numpy.repeat(u[-1], P-M)])
[10]:
def prediction(u, t=tpredict, x0=x0):
"""Predict the effect of an input signal"""
t, y, x = scipy.signal.lsim(G, u, t, X0=x0, interp=False)
return y
[11]:
plt.plot(tpredict, prediction(extend(u)))
[11]:
[<matplotlib.lines.Line2D at 0x1c1475ccf8>]
[12]:
def objective(u, x0=x0):
"""Calculate the sum of the square error for the cotnrol problem"""
y = prediction(extend(u))
return sum((r - y)**2)
This is the value of the objective for our step input:
[13]:
objective(u)
[13]:
3.506966650333838
Now we figure out a set of moves which will minimise our objective function
[14]:
result = scipy.optimize.minimize(objective, u)
uopt = result.x
result.fun
[14]:
0.0009187720232727162
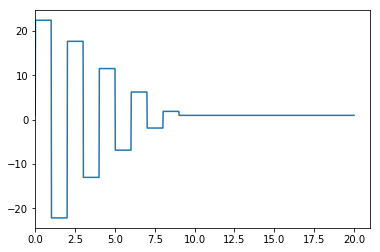
Resample the discrete output to continuous time (effectively work out the 0 order hold value)
[15]:
ucont = extend(uopt)[((tcontinuous-0.01)//DeltaT).astype(int)]
Plot the move plan and the output. Notice that we are getting exactly the output we want at the sampling times. At this point we have effectively recovered the Dahlin controller.
[16]:
def plotoutput(ucont, uopt):
plt.figure()
plt.plot(tcontinuous, ucont)
plt.xlim([0, DeltaT*(P+1)])
plt.figure()
plt.plot(tcontinuous, prediction(ucont, tcontinuous), label='Continuous response')
plt.plot(tpredict, prediction(extend(uopt)), '-o', label='Optimized response')
plt.plot(tpredict, r, label='Set point')
plt.legend()
[17]:
plotoutput(ucont, uopt)
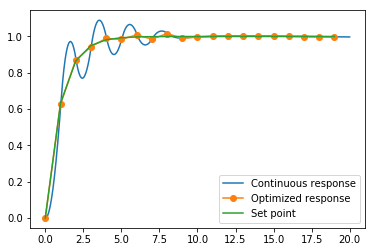
One of the reasons for the popularity of MPC is how easy it is to change its behaviour using weights in the objective function. Try using this definition instead of the simple one above and see if you can remove the ringing in the controller output.
[18]:
def objective(u, x0=x0):
y = prediction(extend(u))
umag = numpy.abs(u)
constraintpenalty = sum(umag[umag > 2])
movepenalty = sum(numpy.abs(numpy.diff(u)))
strongfinish = numpy.abs(y[-1] - r[-1])
return sum((r - y)**2) + 0*constraintpenalty + 0.1*movepenalty + 0*strongfinish